
BillionToOne IPO
BillionToOne is filing for IPO. They have an exciting “single molecule NGS” solution. If that was really single molecule that would be very exciting! After all we have two single molecule sequencers on the market (PacBio and ONT). So if BillionToOne was deriving significant value ($150M+ revenue) from single molecule sequencing, this would be quite exciting.
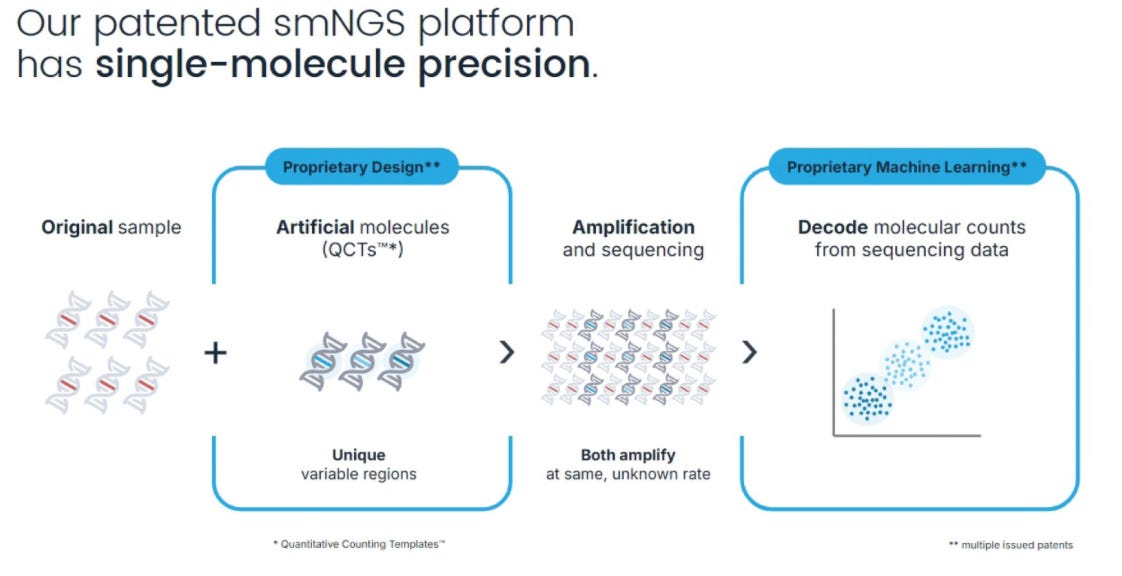
But BillionToOne isn’t “single molecule sequencing” in the way anyone else uses the term “single molecule sequencing”, that is to say “sequencing single molecules”. This is… spike in controls!1
BillionToOne don’t disclose the backend sequencing tech, so it could be PacBio or ONT. But for a counting application like this using short reads, it seems far more likely they are using Illumina or similar short read sequencers.
So, is every NGS platform released since the Solexa Genome Analyzer in 2006 a single molecule sequencer2? If you think so BillionToOne is “single molecule NGS”. But this seems like an odd way to use the term…
What does BillionToOne use this spike-in calibration technology for? NIPT:

They run about 500K tests a year (running at a loss).
The main sell seems to be an expanded panel looking at point mutations causing “SCD, alpha thalassemia, beta-thalassemia, CF, and SMA”.
I personally would be surprised if their spike-in calibration was required to enable this, other approaches seem to work. If some kind of calibration is required, I would be surprised if the IP would hold up sufficiently to exclude other players from using similar approaches.
It seems like Natera are also moving into this space. So I’d expect BillionToOne to see increasing competition here, and I’m doubtful that Natera need BillionToOne’s IP to enable this when they launch.
That said, BillionToOne appears to have a reasonable foothold in this market. So it will be interesting to see how it all plays out.
Was this useful? Please subscribe. Even free subscription help grow the substack.
“QCTs are used in our testing workflow with the following steps:
(1) Add an aliquot of traceable and specific QCTs into the patient’s blood sample, which contains an unknown number of DNA fragments of interest (m1) among a vast background of the patient’s genome. The precise number of QCT molecules (n1) is also unknown at this stage but is determined in a subsequent step.
(2) Amplify the cfDNA fragments of interest using PCR at the same, unknown amplification rate as QCTs.
(3) Count the number of clusters of sequences with identifier tags (i.e., the number of distinct QCTs with different diversity regions), which is equal to the number of QCTs that were added to the sample (n1).
(4) Determine the amplification multiplier (x) by dividing the number of total sequencing reads that map to QCTs by the number of QCTs (n1).
(5) Remove bias by dividing the total number of sequencing reads that map to cfDNA fragments of interest by x to find the absolute number of molecules in the cfDNA sample (m1).
We believe that QCTs provide unprecedented insight into disease biology across the human genome. We have developed custom machine learning models to analyze the tiny, individualized variations across hundreds of thousands of patients, uncovering novel patterns of disease biology. These insights are incorporated into our assays to significantly improve performance. We continuously refine our understanding of disease biology to support existing and future diagnostic products.”
All these sequencers build clusters from a single molecule template. So you get a single from what was at one point a single molecule. Normally we don’t call these single molecule sequencers however. But you can if you like! I’m not your mom! Does anyone read the footnotes anyway?
It does seem like a rather trivial innovation. Isn't NIPT for trisomy already based on the ratios of chromosome 21 to say chromosome 1, so there's already a kind of internal control?