
Everything Wrong With: "Illumina: The Measurement Monopoly" Part 2/8
I’ve created a second substack bitsof.bio. The first post is already up. The plan is to use that for quick short posts, without overwhelming things here. Those interested in more content are most welcome there. Anyway… back to our regularly scheduled programming:
Century of Biology still has 10x the subscriptions I do… in the second part of our continuing series we examine the second sentence from this article:
“The resulting explosion of genomic data has played a central role in transforming biology into an information science.”
I don’t understand this statement, it sounds very nice. But I don’t understand what it means. Let’s try and break it down.
What is Information Science?
I don’t know what an “information science” is…
Did we not use information previously in Biology? Didn’t I read something about a chap called Mendel collecting a lot of information on peas? Some have even suggested he may have… “cleaned” his data, making him truly worthy of the title of “data scientist”.
Wasn’t there another chap called Fisher? Who did some rather important things with data, statistics and genetics?
So… what the hell is an information science anyway? Were we not doing it already?
Let’s go and find a definition:
“Information science focuses on understanding problems from the perspective of the stakeholders involved and then applying information and other technologies as needed. In other words, it tackles systemic problems first rather than individual pieces of technology within that system.”1
A statement that to me only further supports the notion that any field that has the word “science” in its name is guaranteed thereby not to be a science2.
Biology for at least the last 100 years has been concerned (much like most other disciplines) with the accumulation and analysis of data. This hasn’t really changed.
What has changed is that next-gen sequencers produce a lot more data. More data than you can often comfortably process on your laptop in Excel. This has come as a shock too many Biologists I’m sure.
But pretty much every other field has gone through this. And…
Genomics Has It Easy
Folks like to talk about how much data next-gen sequencers produce. How hard it is to perform the data analysis, and how much harder than we have it than anybody else.
The reality is it’s shockingly easy in comparison to other fields…
Data And Data Rates
The NovaSeq X Plus can produce 16 Terabases of data in 48 hours. Each base contains 2 bits of information so that’s roughly 4 Terabytes of data. Or 83 Gigabytes per hour.
The iPhone 15 can record highres video at data rates of ~102 Gigabytes per hour3.
A $1000 smartphone has higher data rates than a $1.25M DNA sequencer...4
Other scientific disciplines have it way harder…
CERN has more than an Exabyte of storage for its experiments. The sequence read archive is tiny by comparison at less than 50 Petabytes!5 (~20x smaller).
In astronomy datasets are also huge. The observatory (LSST) produces 7 Petabytes of data per year. That’s one site!
For this post I tried download a single JWST dataset… I gave up after 40 Gigabytes.
Compute
Our datasets are generally so small that we use interpreted languages like Python to process them. I routinely come across data pipelines that could be made 10 to 100 times faster… but it often just isn’t worth the effort because our datasets are so small.
In sequencing we can increase the number of CPUs we throw at a problem, and generally expect linear increase in speed. That’s not always the case in other in other disciplines. Take molecular dynamics simulations for example. Every timestep all cores need to receive updates from all other cores. This increased communication load, means that scaling falls off with core count:
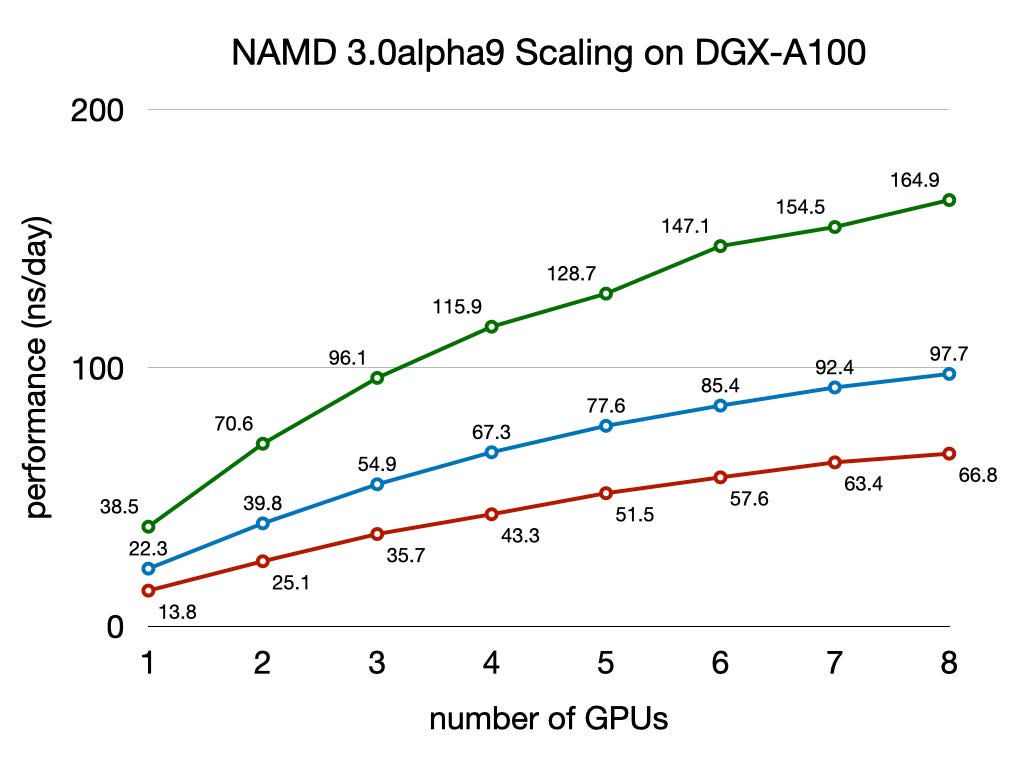
Summary
Next-gen sequencers produce a lot of data. But it’s actually far less than many other applications and the computation and storage requirements are often overstated.
Next-gen sequencer has resulted in a huge increase in the amount of genomic data we have available. And yes, you can’t just use your laptop to analyze datasets in many cases.
But empirical science has always relied on data collection because…

https://en.wikipedia.org/wiki/Information_science
https://quoteinvestigator.com/2015/06/26/not-science/
This isn’t even unprocessed data. The sizes mentioned at the compressed ProRes file sizes, compression is performed on the fly: https://www.apple.com/final-cut-pro/docs/Apple_ProRes.pdf
Yes, there are all kinds of caveats on this “what about quality scores” etc. but they’re at least in the same ballpark.
Currently listed at 12 Petabytes here: https://datascience.nih.gov/data-ecosystem/sra but I suspect this is out of date. I saw another statement suggesting it was around 17 Petabytes. And an article suggesting it would reach 50 Petabytes in 2023.