
Roche Axelios Read Length
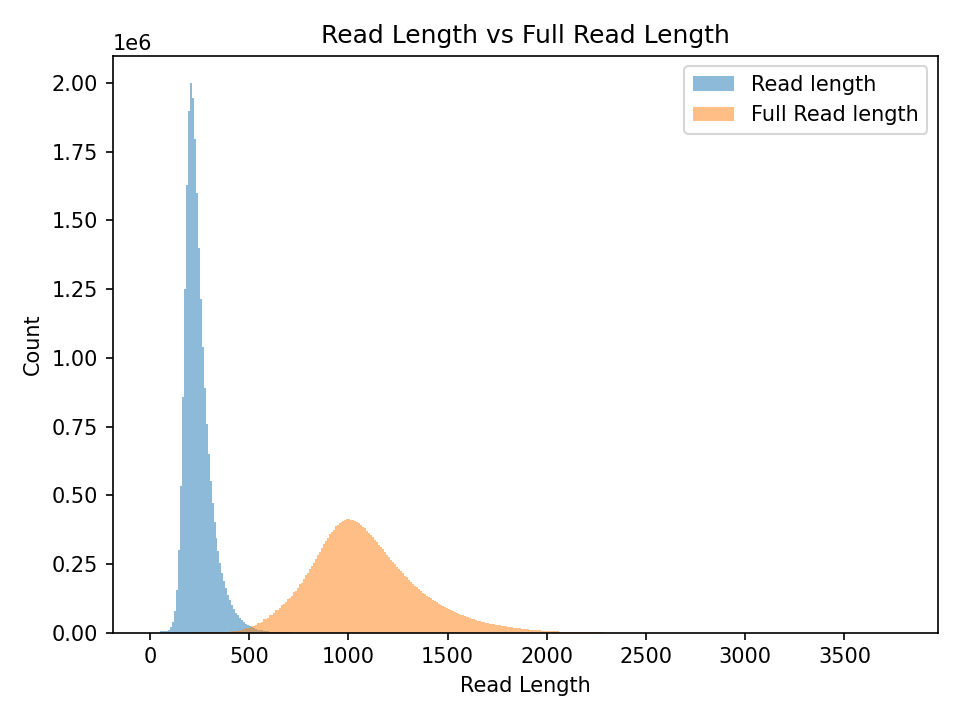
Following on from my post yesterday someone on the Discord suggested I look on the “raw” read length based on the Q values. That is double all the duplex bases + the partial bases. This is indeed a great idea, and in shown in the plot above for the same 10Gb dataset discussed yesterday.
The “full” read length sits at around 1000 base pairs. This is more than double the average duplex read length. As we saw yesterday reads with partial bases are on average longer. Thinking this though on the Discord, I think it’s not that partial bases make reads longer but that if you have a longer initial template, it’s more likely to end up being a partial read.
That is, if template was long and based on the efficiency1 of the duplex creation process it ends up not being fully converted into a duplex. This makes sense to me.
The other interesting point is how gaussian the distribution looks. There’s clearly a tail off to the right, but this is somewhat unlike other single molecule platforms.
